GOS je korpus GOvorjene Slovenščine. Obsega transkripcije okrog 120 ur posnetkov (po)govora v najrazličnejših situacijah, ki smo jim izpostavljeni vsak dan: od radijskih in televizijskih oddaj prek šolskih ur in predavanj do zasebnih pogovorov med prijatelji ali v krogu družine ter raznih delovnih sestankov, svetovanj, pogovora ob prodaji, storitvah ipd. Zapis govora na posnetkih je narejen v dveh različicah, standardizirani in pogovorni, ter obsega več kot milijon besed. Po korpusu lahko iščemo prek spletnega vmesnika na teh spletnih straneh, za vsak izpis iz korpusa pa je mogoče tudi slišati pripadajoči del posnetka. Korpus je nastajal v okviru projekta Sporazumevanaje v slovenskem jeziku.
Zato ker vemo zelo malo o tem, kako govorimo v vsakdanjem življenju. V slovnicah, slovarjih, šolskih učbenikih slovenščine in pri pouku slovenščine se v glavnem ukvarjamo s tem, kako slovenščino pišemo in kako naj bi jo govorili v njeni standardni različici. Dialektologija na drugi strani ve precej o tem, kakšni so (bili) glasoslovni sestavi, oblikoslovne paradigme in besedje »čistih« narečij, ki jih govorijo stari ljudje in ki danes bliskovito izginjajo. Toda niti predpisane standardizirane slovenščine niti čistega narečja v vsakdanjem življenju ne slišimo pogosto in le redko kdo med nami zna govoriti eno ali drugo. Kakšno slovenščino torej v resnici govorimo? To lahko izvemo le tako, da jo posnamemo v njeni čim bolj avtentični različici, jo zapišemo ter nato raziščemo in poslušamo. Zato smo zgradili GOS.
Seveda vsem tistim, ki želijo raziskovati govorjeno slovenščino, bodisi z jezikoslovnega bodisi s kakega drugega, recimo sociološkega ali jezikovnotehnološkega vidika. Toda krog uporabnikov je širši: GOS-ov spletni vmesnik je uporabniško nadvse prijazen in enostaven, zato da bi ga uporabljali tudi učitelji v šoli pri pouku slovenščine ali v jezikovnih tečajih za tujce, lektorji govora na radiu, televiziji ali v gledališču, tolmači, pisci in drugi, ki se tako ali drugače srečajo z vprašanji, povezanimi z govorjeno slovenščino.
Posnetki govora, zajeti v GOS, so zbrani tako, da bi bil korpus čim bolj reprezentativen za današnjo govorjeno slovenščino v najpogostejših vsakdanjih situacijah. Tabela 1 prikazuje, kako je bila zasnovana in kako realizirana vsebina GOS-a.
Tabela 1: Besedilnovrstni kriteriji za zajem gradiv in dejanska pokritost posameznih kategorij v GOS-u. Stanje na dan 6.11.2012.
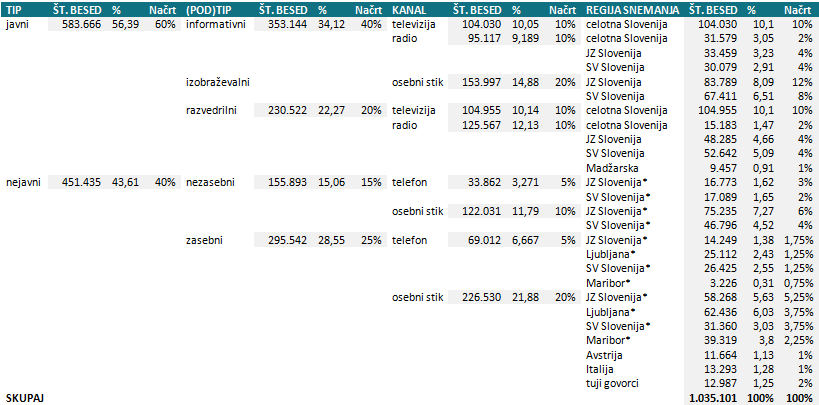
* Označene kategorije so uravnotežene tudi po demografskih kriterijih (glej tabelo 4).
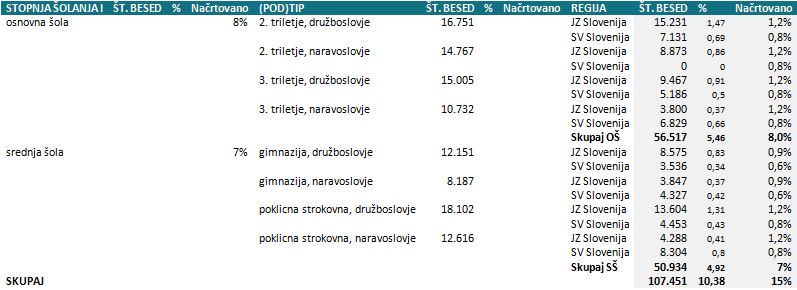
Poseben podsklop korpusa GOS (10% korpusa) predstavlja šolski diskurz, ki je v tabeli 1 predstavljen pod kategorijami javni izobraževalni, osebni stik. Zasnovan in realiziran je bil tako, kot prikazuje tabela 2.
Tabela 2: Kriteriji in pokritost šolskega diskurza v korpusu GOS. Stanje na dan 6.11.2012.
V korpusu GOS so zajeti predvsem posnetki iz let 2008-2010, kot prikazuje tabela 3.
Tabela 3: Zajem posnetkov za GOS po letih. Stanje na dan 6.11.2012.

Poleg reprezentativnosti situacij je bil pri snemanju gradiv za GOS upoštevan tudi kriterij reprezentativnosti govorcev, zato je v tistem delu, ki zajema posnetke zasebnih pogovorov, zajet ustrezen delež govorcev iz različnih regij, obeh spolov, različnih starosti ter različnih izobrazbenih ravni, kot prikazuje tabela 4.
Tabela 4: Demografski kriteriji za zajem gradiv in dejanska pokritost posameznih kategorij v GOS-u. Stanje na dan 6.11.2012.
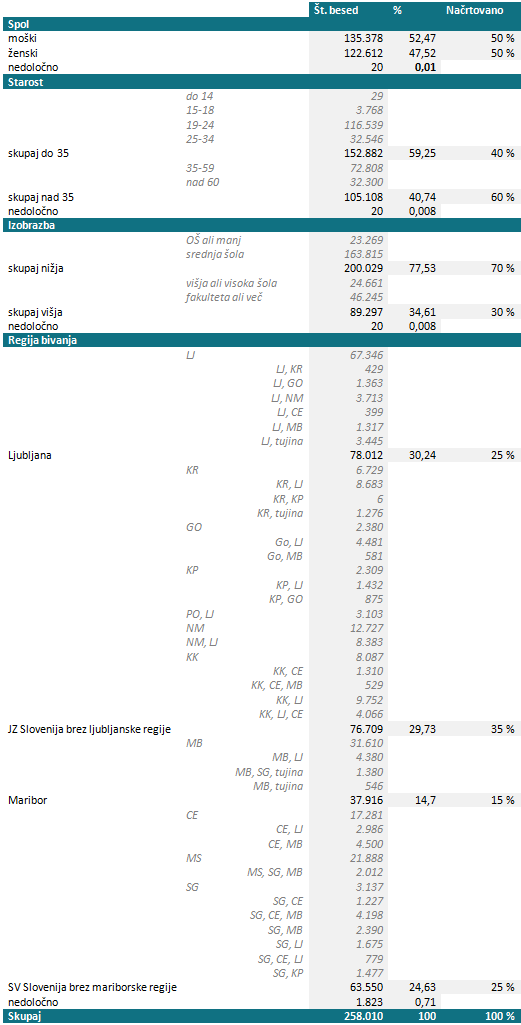
Seveda pa se je ob tem treba zavedati, da bi bil za pravo reprezentativnost korpusa potreben veliko večji vzorec, kot je obstoječih 120 ur govora. Pravi reprezentativni korpusi obsegajo po več 100 milijonov besed, GOS le 1 milijon. Zato upamo, da bo v prihodnosti še rasel.
Lastnik korpusa Gos je Ministrstvo za izobraževanje, znanost, kulturo in šport Republike Slovenije. Pogodba med Ministrstvom in izvajalci projekta določa, da se za prenos baz podatkov na tretje osebe in označevanje avtorskih del uporabi licenca »priznanje avtorstva« + »nekomercialno« + »deljenje pod istimi pogoji«, ki dovoli uporabnikom avtorsko delo in njegove predelave reproducirati, distribuirati, dajati v najem, priobčiti javnosti in predelovati samo pod pogojem, da navedejo avtorja, da ne gre za komercialno uporabo in da tudi oni naprej širijo izvirna dela ali predelave pod istimi pogoji.

To delo je ponujeno pod licenco Creative Commons Priznanje avtorstva-Nekomercialno-Deljenje pod enakimi pogoji 2.5 Slovenija
S klikom na povezavo lahko na računalnik prenesete:Korpus je opisan v:
Verdonik, Darinka, Zwitter Vitez, Ana, 2011: Slovenski govorni korpus Gos. Ljubljana: Trojina, zavod za uporabno slovenistiko.
Mnoge spletne strani shranjujejo informacije o vaši dejavnosti na spletni strani. Te informacije se shranijo na vašem računalniku v obliki majhnih datotek, ki jih imenujemo piškotki.
Na tej spletni strani uporabljamo naslednje piškotke:
Upravljanje s piškotki
Če želite omogočiti piškotke potem v obvestilu na vrhu strani kliknite možnost "SPREJMEM PIŠKOTKE". Če ne želite omogočiti piškotkov potem kliknite možnost "NE SPREJMEM PIŠKOTKOV". Če obvestila ne vidite ali pa želite spremeniti svojo odločitev potem kliknite tukaj. Navodila za izključitev storitve Google Analytics najdete na spletni strani http://tools.google.com/dlpage/gaoptout.

